
Build AI faster, easier, and more useful
Empower your AI journey with HyperAI — effortlessly train and deploy models, customize with advanced graph computing, and slash costs by up to 87.5%, all through a fully graphical interface.
- gpu_count
- 3,000+
- community_users
- 500k+
- total_trained
- 10,000+ hours
- datasets_hosted
- 20k+
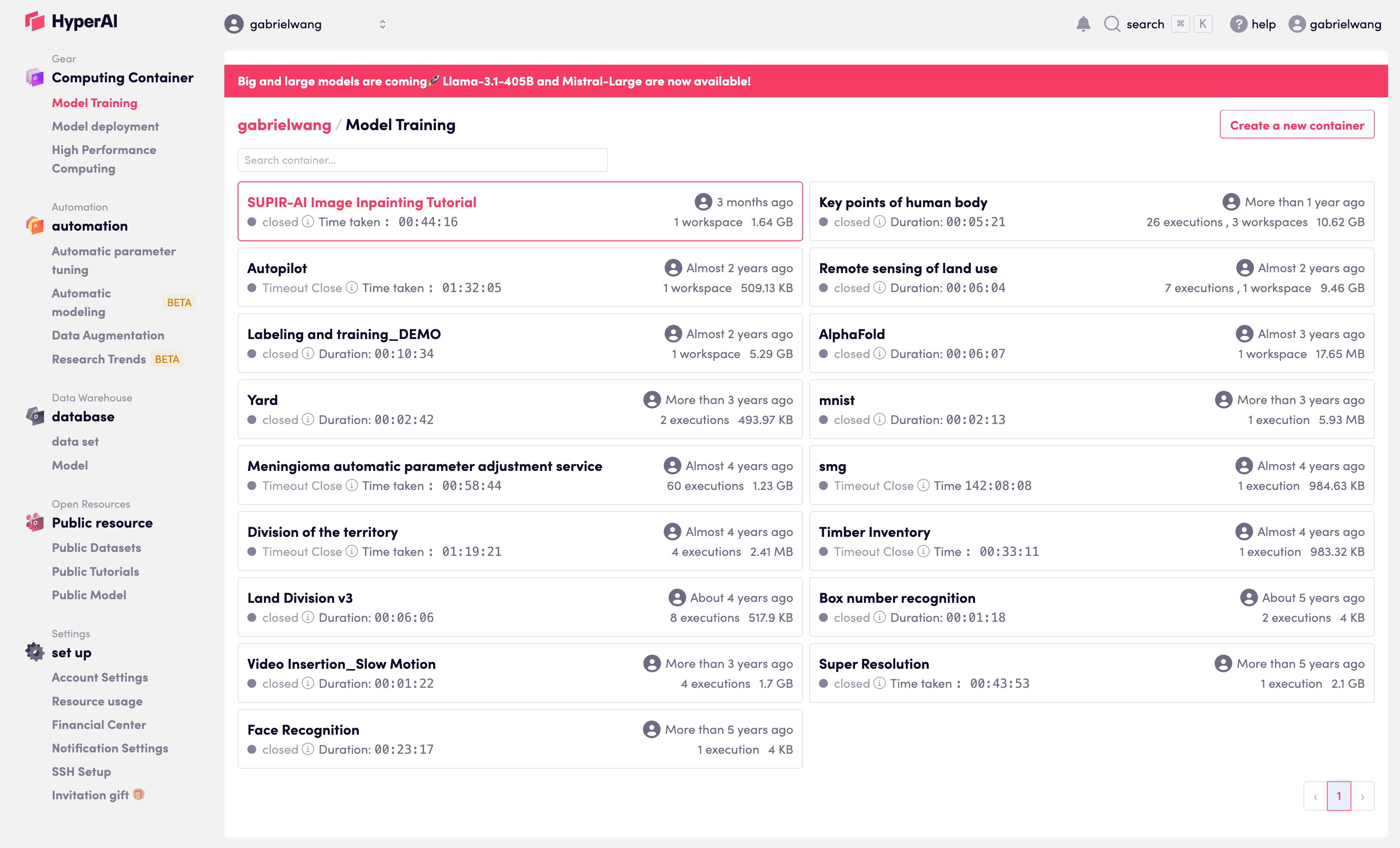
Simplify model training tasks.
HyperAI’s intuitive interface, cost-saving optimizers, and advanced deep RAG solutions elevate your AI performance effortlessly.
Out-of-the-Box
With just a few clicks, you can train and deploy AI models, arrange prompts, and build workflows with ease.
Our fully graphical construction and monitoring interface makes your AI customization journey simpler and more convenient.
Cost Savings
HyperAI's self-developed optimizers and sparsification methods can reduce your costs by up to 87.5%.
While maintaining the full optimization effect of your models. Combined with TVM's compilation optimization, your training and inference costs can be significantly reduced.

Highly Customizable
Our unique deep RAG solution integrates graph computing into the RAG process.
It provides you with a knowledge experience far superior to ordinary search enhancement. Coupled with our flexible and usable workflow editing system, you can greatly enhance the intelligence level of your AI agents.

With just a few clicks, you can train and deploy AI models, arrange prompts, and build workflows with ease.
Our fully graphical construction and monitoring interface makes your AI customization journey simpler and more convenient.
HyperAI's self-developed optimizers and sparsification methods can reduce your costs by up to 87.5%.
While maintaining the full optimization effect of your models. Combined with TVM's compilation optimization, your training and inference costs can be significantly reduced.
Our unique deep RAG solution integrates graph computing into the RAG process.
It provides you with a knowledge experience far superior to ordinary search enhancement. Coupled with our flexible and usable workflow editing system, you can greatly enhance the intelligence level of your AI agents.
Solutions
HyperAI enhances AI with advanced RAG technology and efficient training, offering faster Nvidia GPU performance, extensive datasets, and secure enterprise deployment options.
- Deep RAG
- Traditional RAG technology often can only utilize original text fragments, lacking the deep "thinking" of intelligent agents. Our deep RAG technology introduces a directed acyclic graph organization method to process data vectors, making the RAG-related calculations more aligned with the reasoning process of large language models, thereby significantly optimizing the intelligence level of AI agents.
- Model Training
- HyperAI has introduced Chen Xingshen's "Gauss-Bonnet-Chen" formula into the optimizer calculation process, reducing the GPU memory requirements of LLM training and fine-tuning by over 80%. This significantly increases GPU utilization and saves training costs.
- Model Deployment
- Based on Triton and corresponding operator library optimizations, HyperAI has increased the inference speed of models by up to 4.6 times compared to vLLM on the same Nvidia GPU. This dramatically reduces the hosting costs of open-source models.
- Built-in Resources
- HyperAI comes with a wealth of data science and AI research datasets that can be enabled with a single click. We are committed to building the most comprehensive set of built-in resources to make your AI journey more convenient and faster.
- Dedicated Deployment
- In addition to our online services, we also provide dedicated deployment services for large-scale enterprises. To meet your data security and compliance requirements, we offer the most comprehensive service experience.




Stay up to date
Get updates on all of our latest news and be the first to get notified when public beta release.